Azure AI Foundry supports deploying large language models (LLMs). In this article, we will see how to deploy a model and use it.
Azure AI Foundry Portal
- Select your project - My assets - Models + endpoints - Deploy model
- Click Deploy base model
- Select the model you want to deploy (here I am selecting gpt-4.1) and click Confirm

- You can see the deployment details like capacity (token per minute), resource location etc.
- Click on Create resource and deploy

- Now it will start creating the resource and this step may take a minute or so.
- Once it is done, it will take you to the following page where you can see the mode details on the model you just deployed.

- Click on Open in playground to test the model.
- Once the chat playground is open, you will see your deployment, and under that you will see a section where you can give the model instructions and context. An example is given in the following screenshot. Once the model instructions and context are provided make sure to click Apply changes button.
- Now you can click on Generate prompt, provide the query and click on Send.
- You can also set values for limiting the maximum output token for the model response, temperature, frequency penalty etc. under the Parameters section.

- A sample response is provided in the following screenshot.

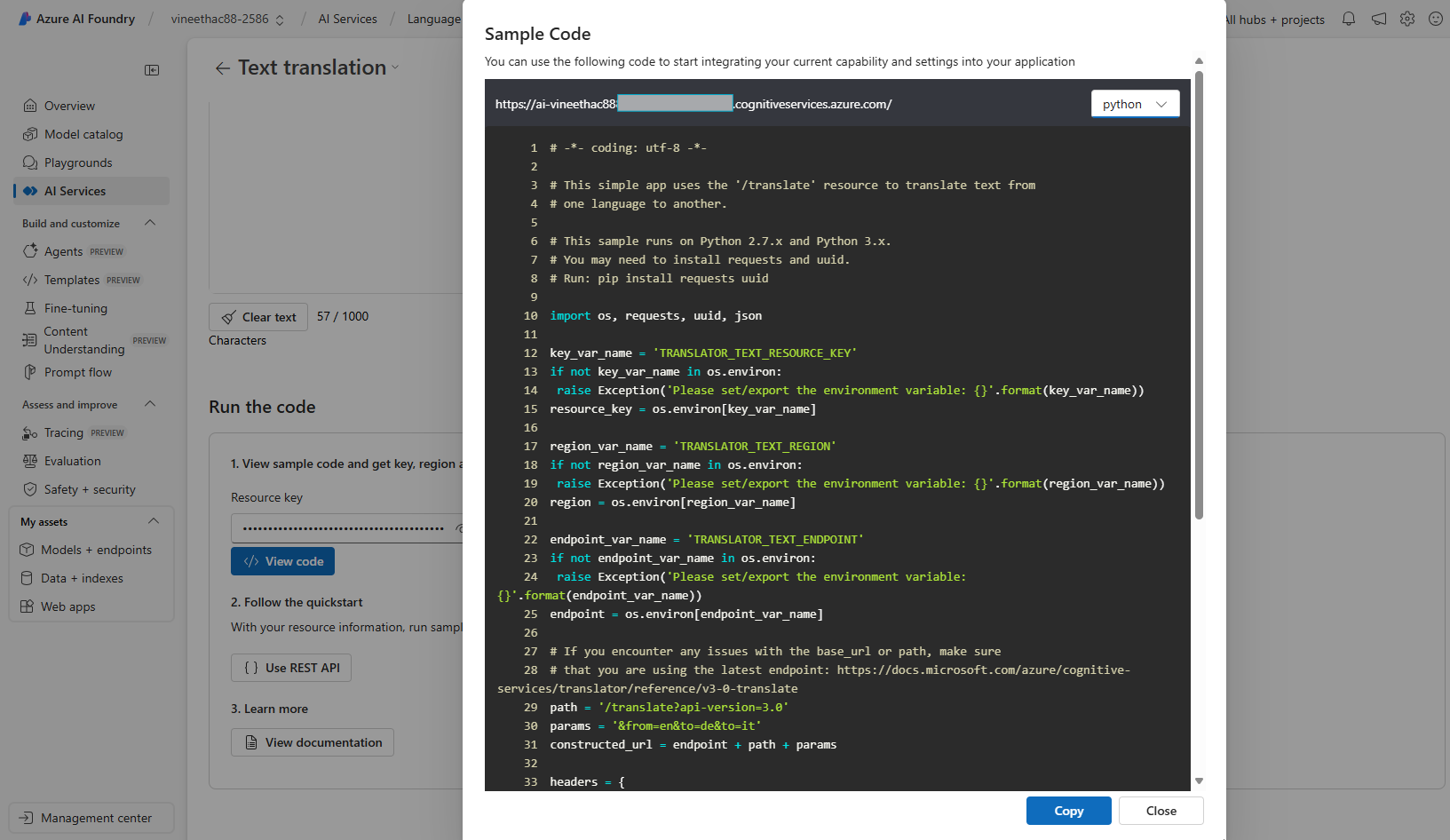
- To see the sample code, you can click on View code.

- You can also see code samples and authentication using API key as shown below.

- Metrics (total requests, token count, etc.) related to your LLM model deployment can be found on the following page.

Python
Sample code to interact with the model can be found in my GitHub repo.
Hope it was useful. Cheers!