In this article, I will show you how to use an Azure AI Service available within the Azure AI Foundry project. We'll use the language translator as an example.
Azure AI Foundry portal
- Select AI Services.
- Click on Language + Translator.
- Click on Try with your own.
- Here I am translating language from English to Malayalam. Take a look at the Connected Azure AI Services, you can see it is already connected to one. Incase if it is not connected to an Azure AI Services resource, you can click on Create a new AI Services resource, select a region, provide an AI Services name if you like to and click Create and connect.
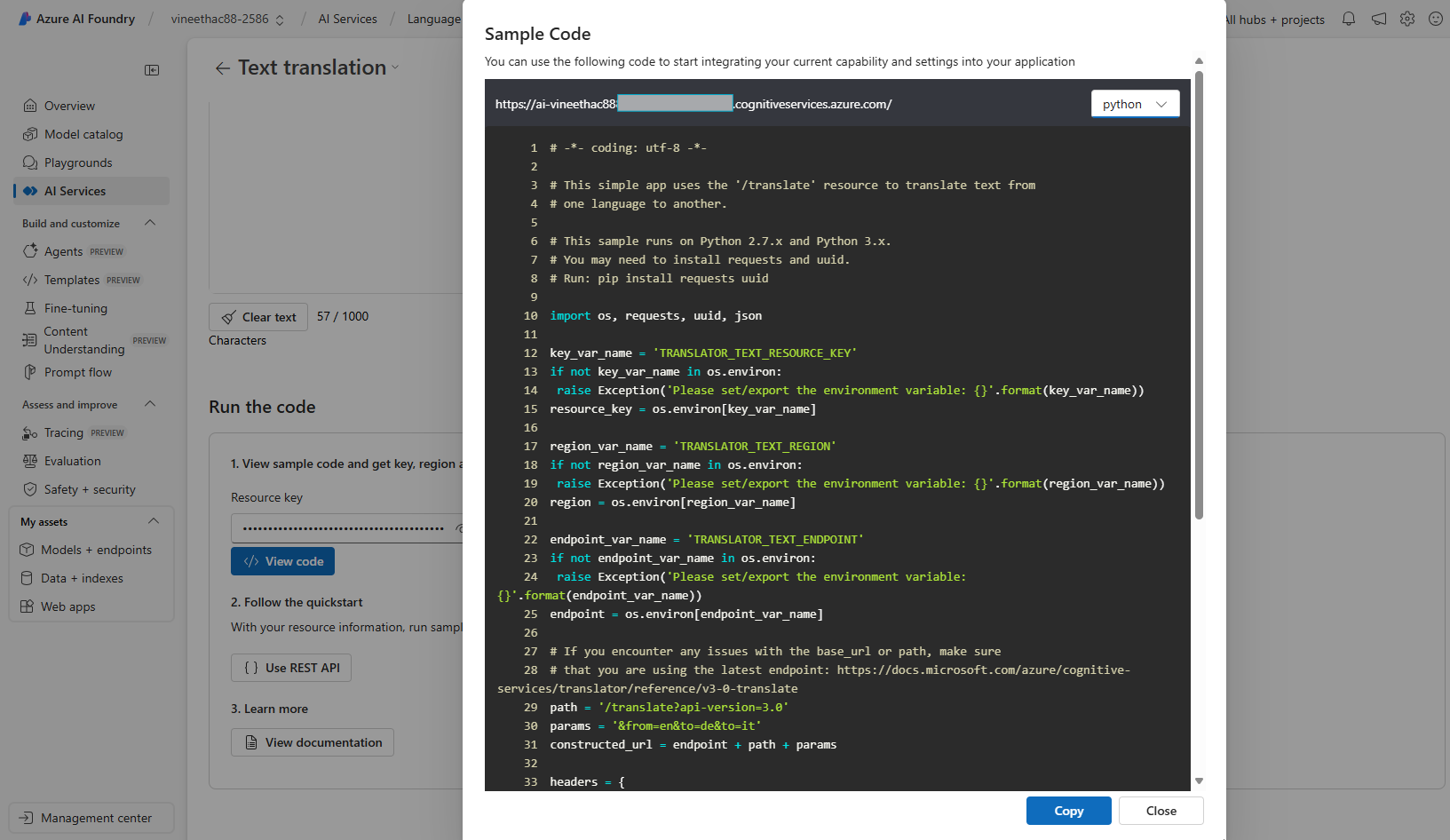
- You can also view the sample code by clicking on View code.
- Here is the sample code in Python and when you scroll down you can find the Resource key and Region details.
Python
import os, requests, uuid, json
resource_key = 'resource_key_here'
region = 'region_here'
endpoint = 'https://api.cognitive.microsofttranslator.com/'
# If you encounter any issues with the base_url or path, make sure
# that you are using the latest endpoint: https://docs.microsoft.com/azure/cognitive-services/translator/reference/v3-0-translate
path = '/translate?api-version=3.0'
params = '&to=ml'
constructed_url = endpoint + path + params
headers = {
'Ocp-Apim-Subscription-Key': resource_key,
'Ocp-Apim-Subscription-Region': region,
'Content-type': 'application/json',
'X-ClientTraceId': str(uuid.uuid4())
}
# You can pass more than one object in body.
body = [{
'text' : 'where are you right now?'
}]
request = requests.post(constructed_url, headers=headers, json=body)
response = request.json()
print(json.dumps(response, sort_keys=True, indent=4, separators=(',', ': ')))
Sample output:
What you see is a unicode string and once it is converted you will see the corresponding Malayalam text.
Curl
curl -X POST "https://api.cognitive.microsofttranslator.com/translate?api-version=3.0&to=ml" \
> -H "Ocp-Apim-Subscription-Key: your_key_here" \
> -H "Ocp-Apim-Subscription-Region: your_region_here" \
> -H "Content-Type: application/json" \
> -d "[{'Text':'where are you now?'}]" -v
Sample output:
Hope this was useful. Cheers!
References






























.jpeg)
