Encountering issues with connectivity to your TKC apiserver/ control plane can be frustrating. One common problem we've seen is the kubeconfig failing to connect, often due to missing server pool members in the load balancer's virtual server (LB VS).
The Issue
The LB VS, which operates on port 6443, should have the control plane VMs listed as its member servers. When these members are missing, connectivity problems arise, disrupting your access to the TKC apiserver.
Troubleshooting steps
- Access the TKC: Use the kubeconfig to access the TKC.
❯ KUBECONFIG=tkc.kubeconfig kubectl get node
Unable to connect to the server: dial tcp 10.191.88.4:6443: i/o timeout
❯
- Check the Load Balancer: In NSX-T, verify the status of the corresponding load balancer (LB). It may display a green status indicating success.
- Inspect Virtual Servers: Check the virtual servers in the LB, particularly on port 6443. They might show as down.
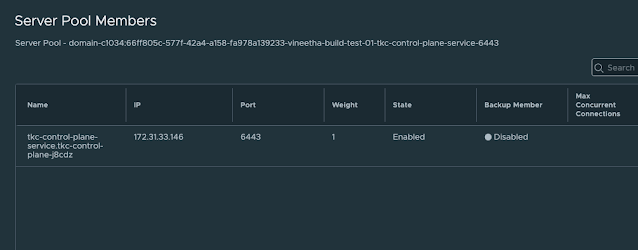
- Examine Server Pool Members: Look into the server pool members of the virtual server. You may find it empty.
- SSH to Control Plane Nodes: Attempt to SSH into the TKC control plane nodes.
- Run Diagnostic Commands: Execute diagnostic commands inside the control plane nodes to verify their status. The issue could be that the control plane VMs are in a hung state, and the container runtime is not running.
vmware-system-user@tkc-infra-r68zc-jmq4j [ ~ ]$ sudo su
root [ /home/vmware-system-user ]# crictl ps
FATA[0002] failed to connect: failed to connect, make sure you are running as root and the runtime has been started: context deadline exceeded
root [ /home/vmware-system-user ]#
root [ /home/vmware-system-user ]# systemctl is-active containerd
Failed to retrieve unit state: Failed to activate service 'org.freedesktop.systemd1': timed out (service_start_timeout=25000ms)
root [ /home/vmware-system-user ]#
root [ /home/vmware-system-user ]# systemctl status containerd
WARNING: terminal is not fully functional
- (press RETURN)Failed to get properties: Failed to activate service 'org.freedesktop.systemd1'>
lines 1-1/1 (END)lines 1-1/1 (END)
- Check VM Console: From vCenter, check the console of the control plane VMs. You might see specific errors indicating issues.
EXT4-fs (sda3): Delayed block allocation failed for inode 266704 at logical offset 10515 with max blocks 2 with error 5
EXT4-fs (sda3): This should not happen!! Data will be lost
EXT4-fs error (device sda3) in ext4_writepages:2905: IO failure
EXT4-fs error (device sda3) in ext4_reserve_inode_write:5947: Journal has aborted
EXT4-fs error (device sda3) xxxxxx-xxx-xxxx: unable to read itable block
EXT4-fs error (device sda3) in ext4_journal_check_start:61: Detected aborted journal
systemd[1]: Caught <BUS>, dumped core as pid 24777.
systemd[1]: Freezing execution.
- Restart Control Plane VMs: Restart the control plane VMs. Note that sometimes your admin credentials or administrator@vsphere.local credentials may not allow you to restart the TKC VMs. In such cases, decode the username and password from the relevant secret and use these credentials to connect to vCenter and restart the hung TKC VMs.
❯ kubectx wdc-01-vc17
Switched to context "wdc-01-vc17".
❯
❯ kg secret -A | grep wcp
kube-system wcp-authproxy-client-secret kubernetes.io/tls 3 291d
kube-system wcp-authproxy-root-ca-secret kubernetes.io/tls 3 291d
kube-system wcp-cluster-credentials Opaque 2 291d
vmware-system-nsop wcp-nsop-sa-vc-auth Opaque 2 291d
vmware-system-nsx wcp-cluster-credentials Opaque 2 291d
vmware-system-vmop wcp-vmop-sa-vc-auth Opaque 2 291d
❯
❯ kg secrets -n vmware-system-vmop wcp-vmop-sa-vc-auth
NAME TYPE DATA AGE
wcp-vmop-sa-vc-auth Opaque 2 291d
❯ kg secrets -n vmware-system-vmop wcp-vmop-sa-vc-auth -oyaml
apiVersion: v1
data:
password: aWAmbHUwPCpKe1Uxxxxxxxxxxxx=
username: d2NwLXZtb3AtdXNlci1kb21haW4tYzEwMDYtMxxxxxxxxxxxxxxxxxxxxxxxxQHZzcGhlcmUubG9jYWw=
kind: Secret
metadata:
creationTimestamp: "2022-10-24T08:32:26Z"
name: wcp-vmop-sa-vc-auth
namespace: vmware-system-vmop
resourceVersion: "336557268"
uid: dcbdac1b-18bb-438c-ba11-76ed4d6bef63
type: Opaque
❯
***Decrypt the username and password from the secret and use it to connect to the vCenter.
***Following is an example using PowerCLI:
PS /Users/vineetha> get-vm gc-control-plane-f266h
Name PowerState Num CPUs MemoryGB
---- ---------- -------- --------
gc-control-plane-f2… PoweredOn 2 4.000
PS /Users/vineetha> get-vm gc-control-plane-f266h | Restart-VMGuest
Restart-VMGuest: 08/04/2023 22:20:20 Restart-VMGuest Operation "Restart VM guest" failed for VM "gc-control-plane-f266h" for the following reason: A general system error occurred: Invalid fault
PS /Users/vineetha>
PS /Users/vineetha> get-vm gc-control-plane-f266h | Restart-VM
Confirm
Are you sure you want to perform this action?
Performing the operation "Restart-VM" on target "VM 'gc-control-plane-f266h'".
[Y] Yes [A] Yes to All [N] No [L] No to All [S] Suspend [?] Help (default is "Y"): Y
Name PowerState Num CPUs MemoryGB
---- ---------- -------- --------
gc-control-plane-f2… PoweredOn 2 4.000
PS /Users/vineetha>
- Verify System Pods and Connectivity: Once the control plane VMs are restarted, the system pods inside them will start, and the apiserver will become accessible using the kubeconfig. You should also see the previously missing server pool members reappear in the corresponding LB virtual server, and the virtual server on port 6443 will be up and show a success status.
Following these steps should help you resolve the connectivity issues with your TKC apiserver/control plane effectively.Ensuring that your load balancer's virtual server is correctly configured with the appropriate member servers is crucial for maintaining seamless access. This runbook aims to guide you through the process, helping you get your TKC apiserver back online swiftly.
Note: If required for critical production issues related to TKC accessibility I strongly recommend to raise a product support request.
Hope it was useful. Cheers!
.png)

