Scenario
User is running some latency-sensitive business-critical applications on the vSAN cluster. Below are the symptoms that he would like to define and alerts should be produced for the same and these should affect the "Efficiency" badge of the vSAN cluster object.
- Warning - when vSAN Cluster Read Latency is greater than 1 ms
- Critical - when vSAN Cluster Read Latency is greater than 2 ms
- Warning - when vSAN Cluster Write Latency is greater than 2 ms
- Critical - when vSAN Cluster Write Latency is greater than 3 ms
 |
| Sample screenshot of vSAN environment efficiency badge |
Step1: Add symptom definitions
Go to Alerts - Symptom Definitions - Click Add (+)
Select base object type: vSAN Cluster
Select the metric "Read Latency (ms) - double click on it twice so that you can define both warning and critical symptoms.
Provide symptom definition name, criticality and numeric value as required and click Save.
Now you can see the two symptoms which you have just created.
Similarly, create symptom definitions for vSAN Cluster Write Latency.
All 4 symptom definitions are created now.
Step2: Add alert definitions
Next step is to add alert definitions.
Go to Alerts - Alert Definitions - Click Add (+)
- Provide a name and description.
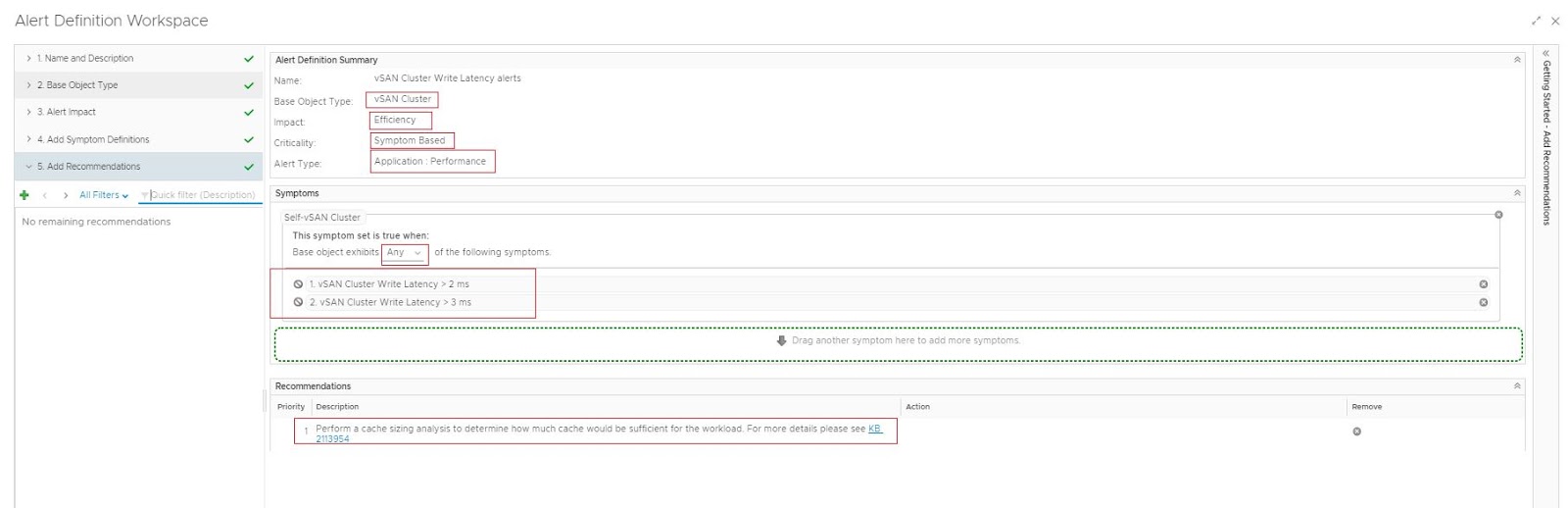
- Click on Base Object Type and select "vSAN Cluster"
- Click on Alert Impact and select Impact: Efficiency (this means this alert definition will affect the efficiency badge)
- Click Add Symptom Definitions (here you have to search for the symptom definitions that were created earlier and attach to this alert definition)
- Drag both symptom definitions to the right-hand side as shown in the screenshot (make sure to choose "Any" as highlighted below)
- Click Add Recommendations (here I added some sample recommendations) and click save
Similarly, create an alert definition for vSAN Cluster Write Latency alerts.
Now both alert definitions are created.

Let's verify current vSAN cluster Read/ Write latency in the dashboard.
As you can see above, Cluster I/O Write Latency is 2.67 ms which is greater than the warning threshold we defined. This means a warning alert should be produced and also should affect the efficiency badge of the vSAN Cluster object. An alert has already produced for this and can be seen in the second widget. It also shows the efficiency badge color is now yellow. If you click on the alert it will provide more details on the same.
If you browse the environment tab you can also notice that the efficiency badge of vSAN Cluster has turned to yellow.
Please feel free to share if this was useful. Cheers!
Related posts