Alerting is a very important aspect of infrastructure monitoring. vROps has very powerful alerting capabilities. It might look a bit complicated for the first time. A good understanding of symptoms, alert definitions, badges, notification rules, etc. are required to effectively utilize the maximum functionality/ capabilities of vROps. In this post, I will try to explain all these alert settings. Before getting into the configurations, first, let's have a look at objects and object types in vROps.
Objects and object types
As you can see in the screenshot above there are many objects of type "Datastore". All these objects/ object types have "Metrics" and "Properties". Click on the "Show Detail" icon as shown below to view more details of the selected object.
Metrics and Properties
"Metrics" and "Properties" of the object "vol03" is shown below.
Symptom definitions and alert definitions
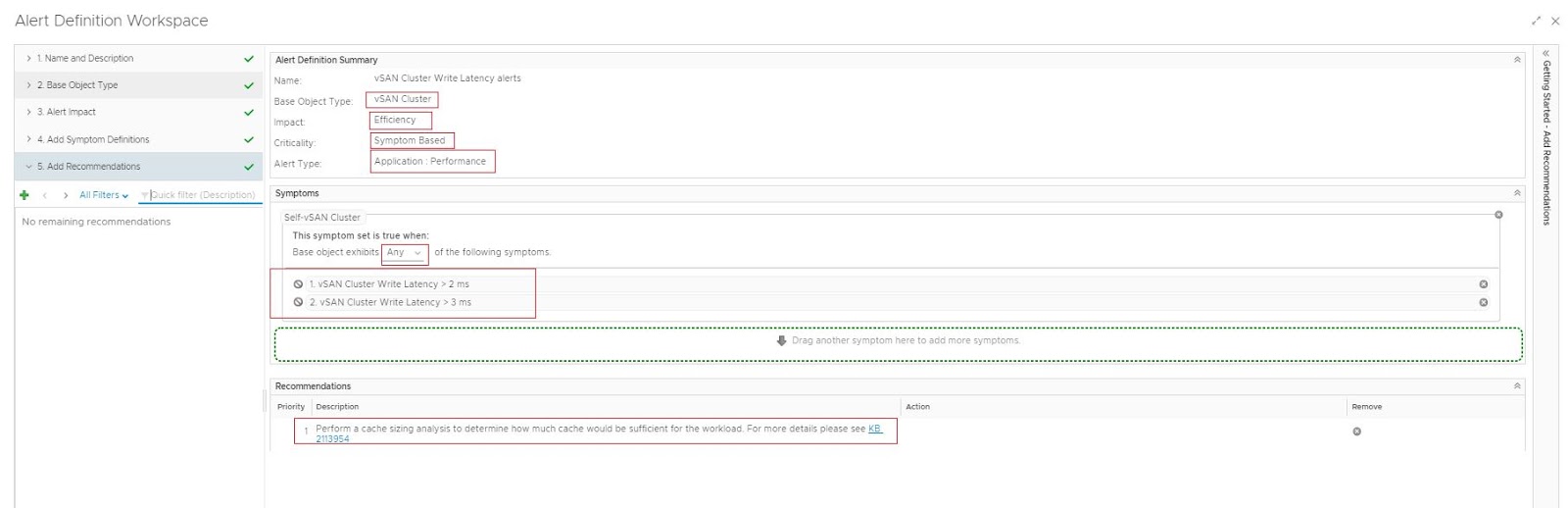
Based on the value of metrics/ property you can define symptoms with criticality Info, warning, critical, etc. Using symptom definitions alert definitions can be created and this generates corresponding alerts and will directly affect the badges associated with the object. Now let's have a look at some of the symptom definitions and alert definitions that are pre-defined in vROps for the "vCenter Adapter". Here I am taking an example of object type "Datastore".
Examples: Symptom definition
Select a symptom definition and click edit.
As you can see, this symptom definition produces a warning alert when any datastore "capacity used %" is greater than 90.
Another symptom definition is given below where an info alert will be generated when space remaining on the datastore is 0.
Example: Alert definition
As shown in the screenshot below there are few pre-defined alert definitions for object type "datastore".
Let's select one alert definition.
Now, if you would like to forward these alerts to an email address or an SNMP trap destination, you will need to configure two things.
- Outbound instance
- Alert notification rules
Add outbound instance
I will be configuring an SNMP trap destination. Go to Administration - Management - Outbound settings - click on the + icon. Provide necessary details and test to ensure the connection is successful.
Add alert notification rule
By default, no notification rules are available in vROps. User has to create new rules as per the requirement. Go to Alerts - Alert settings - Notification settings - click on the + icon and provide necessary configuration details. As an example, I will configure alert notification rule to forward all datastore related alerts to an SNMP trap destination.
The above rule will forward all the alerts that impact health, risk, and efficiency badges of datastore object to the configured SNMP trap destination.
Summary of the alerting process in vROps
Hope it was useful. Cheers!
Related posts