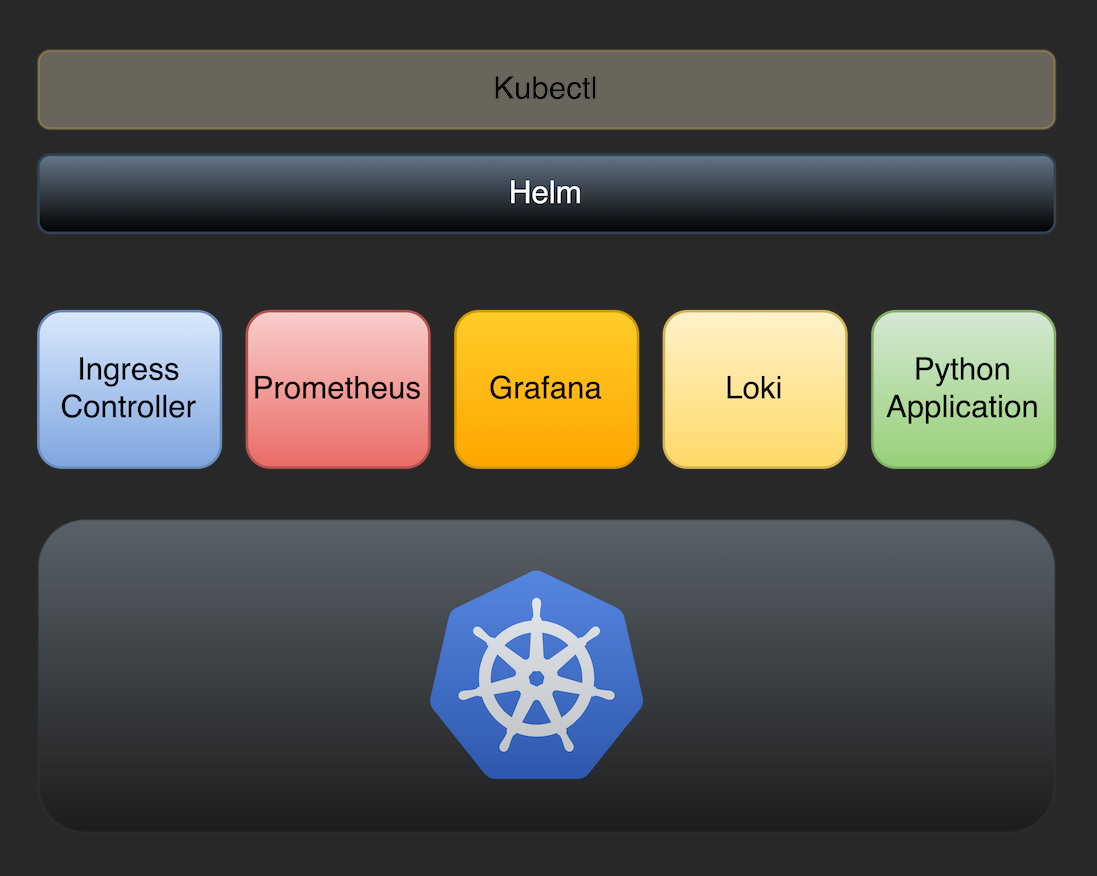
This blog series will help you get started with Hugging Face, including:
- Downloading and using Hugging Face models locally via the Python Transformers library.
- Constructing an API for your LLM application using FastAPI.
- Containerizing your project with Docker.
- Deploying and running your containerized LLM application on a Kubernetes cluster.

An overview about Hugging Face, types of Language Models, and the Transformers library are given in my GitHub repo: https://github.com/vineethac/huggingface/tree/main
Here are some examples of running the language models locally from Hugging Face using Pipeline function from the Transformers library:
question-answering
Model used: distilbert-base-cased-distilled-squad
6-question-answering.py ''' Question answering from a given context. ''' from transformers import pipeline question_answerer = pipeline(task="question-answering", model="distilbert-base-cased-distilled-squad") output = question_answerer( question="What work I do?", context="My name is Vineeth and I work as a Site Reliability Engineer at VMware in Bangalore, India", ) print(output)root@hf-2:/transformers-course# python3 6-question-answering.py {'score': 0.9214025139808655, 'start': 35, 'end': 60, 'answer': 'Site Reliability Engineer'} root@hf-2:/transformers-course#
translation
Model used: Helsinki-NLP/opus-mt-fr-en
8-translation.py ''' Translate from fr to en. ''' from transformers import pipeline translator = pipeline("translation", model="Helsinki-NLP/opus-mt-fr-en") output = translator("Ce cours est produit par Hugging Face.") print(output)root@hf-2:/transformers-course# python3 8-translation.py [{'translation_text': 'This course is produced by Hugging Face.'}] root@hf-2:/transformers-course#
More details and examples are given in my GitHub repo:
https://github.com/vineethac/huggingface/tree/main/1-examples
Hope it was useful. Cheers!