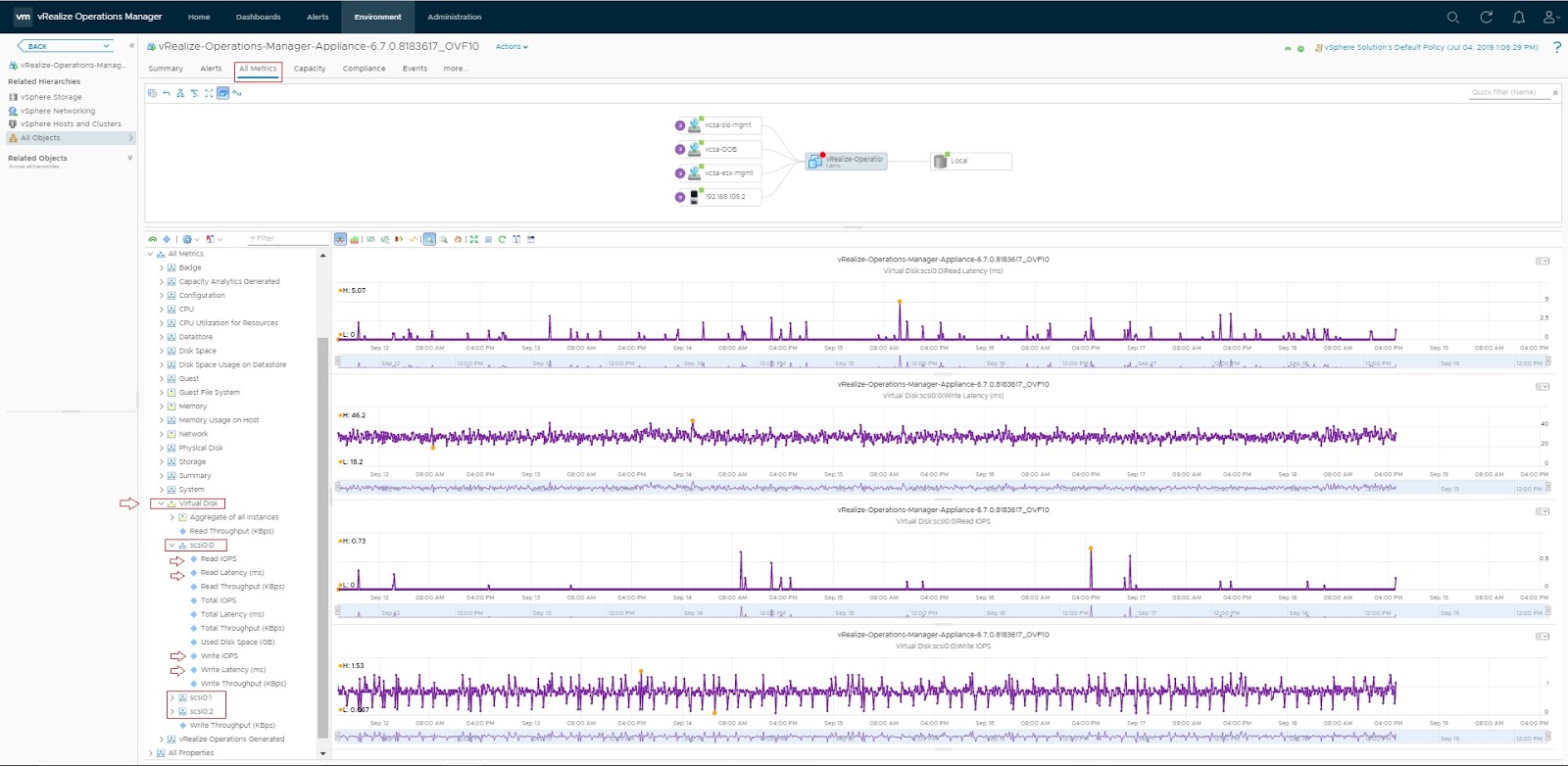
It is very important to monitor and analyze the performance of storage subsystem components as it direcly affects the application performance. In this article, I will briefly explain how to use PowerCLI to get real time storage IOPS and latency of the following:
- Virtual disk
- Datastore
- Disk/ LUN
- Storage adapter
- Storage path
Connect to vCenter server using:
Connect-VIServer <IP address of vCenter>To understand the list of all available stats for a specific entity, you can use Get-StatType. For example, to list all real time stats for a virtual machine you can use:
Get-StatType -Entity <VM name> -Realtime | sort
Virtual disk
To get real-time IOPS and latency of all virtual disks of a VM named 'lustre01':
Get-Stat -Entity lustre01 -Realtime -MaxSamples 1 -Stat virtualDisk.numberReadAveraged.average,virtualDisk.numberWriteAveraged.average,virtualDisk.totalReadLatency.average,virtualDisk.totalWriteLatency.average | sort Instance,MetricId | select MetricId, Value, Unit, Instance
Datastore
To get real-time IOPS and latency of a datastore (with Uuid: 5bea72bb-5d72ed6a-1d85-246e96792988) from an ESXi host (IP: 192.168.105.10):
Get-Stat -Entity 192.168.105.10 -Stat datastore.numberReadAveraged.average,datastore.numberWriteAveraged.average,datastore.totalReadLatency.average,datastore.totalWriteLatency.average -Realtime -MaxSamples 1 -Instance 5bea72bb-5d72ed6a-1d85-246e96792988 | Select MetricId, Value, Unit, Instance | Sort-Object MetricId
Note: You can get Uuid of a datastore using (Get-Datastore vol01).ExtensionData.Info.Vmfs.Uuid
Disk/ LUN
To get real-time IOPS and latency of a disk (eui.387de1af35b93f6ff0a9bef000000000):
Get-Stat -Entity 192.168.105.10 -Disk -Realtime -Instance eui.387de1af35b93f6ff0a9bef000000000 -MaxSamples 1 -Stat disk.numberWriteAveraged.average,disk.numberReadAveraged.average,disk.totalWriteLatency.average,disk.totalReadLatency.average | Select MetricId, Value, Unit, Instance
Storage adapter
To get real-time IOPS and latency of a storage adapter:
Get-Stat -Entity 192.168.105.10 -Realtime -MaxSamples 1 -Stat storageAdapter.totalReadLatency.average, storageAdapter.totalWriteLatency.average, storageAdapter.numberReadAveraged.average, storageAdapter.numberWriteAveraged.average -Instance vmhba64 | Select-Object MetricId, Value, Unit, Instance | Sort-Object MetricId
Storage Path
To get real-time IOPS and latency of a storage path:
Get-Stat -Entity 192.168.105.10 -Realtime -MaxSamples 1 -Stat storagePath.totalReadLatency.average, storagePath.totalWriteLatency.average, storagePath.numberReadAveraged.average, storagePath.numberWriteAveraged.average -Instance fc.300fb123ba76519c:b436362bae5b217-fc.300fb123ba76519c:b436362bae5b217-eui.387de1af35b93f6ff0a9beec00000001 | Select MetricId,Value,Unit,Instance | Sort-Object MetricId
Hope it was useful. Cheers!
Related posts