Benchmarking of IT infrastructure is standard practice and is usually done before putting it into a production environment. It gives you baseline values about different performance aspects of the system/ solution under test. These benchmarking principles are applicable for Kubernetes clusters too. But the test cases and evaluation criteria may slightly vary compared to benchmarking a traditional IT infrastructure.
Following are some of the test considerations:
- Performance of PVCs.
- Time to provision PVCs.
- Read/ Write IOPS and Latency of PVCs.
- Pod startup latency.
- The time consumed to complete the deployment of different K8s objects.
- Statefulset
- Deployment etc.
- Performance behavior of sample application workloads.
- Network performance and connectivity between different K8s nodes.
In this article, I will explain a quick and easy way to benchmark the storage system used by the Kubernetes cluster to provision PVCs for application workloads. I am using FIO to generate storage IOs. You can use the following YAML file to deploy FIO pods as a statefulset. Note that here I am using PowerFlex VVOL datastore as Cloud Native Storage (CNS) for Tanzu K8s clusters and so the storage class "powerflex-storage-policy". This may differ in your case, and you might need to modify it to match the storage class available in your setup.
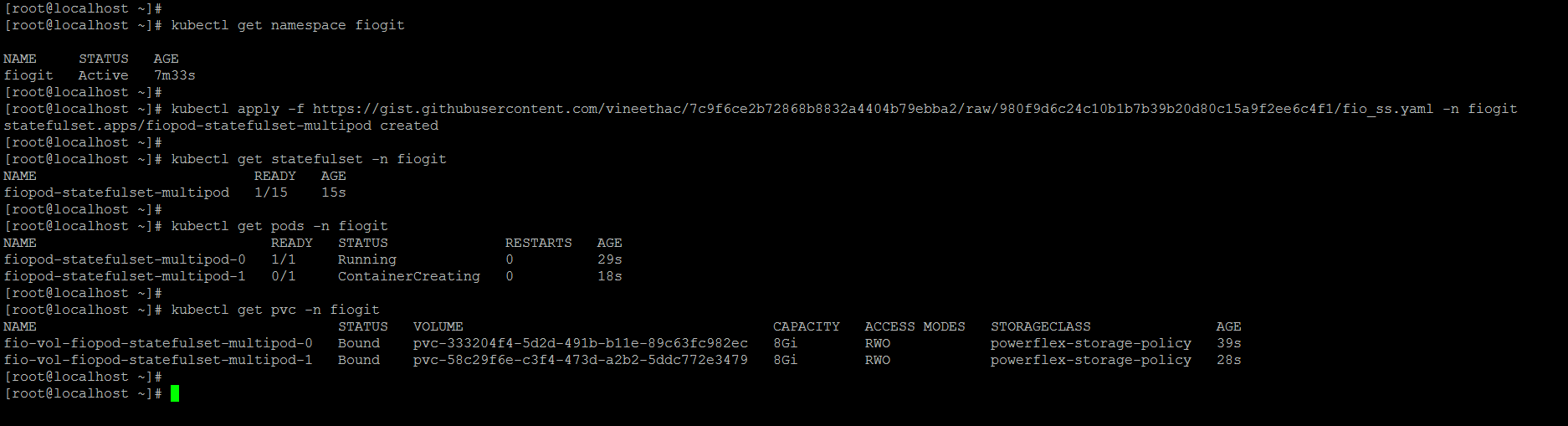
This YAML file will deploy a statefulset with 15 FIO pods (as per the number of replicas mentioned) and will start the storage IO stress test (8k block size, 70% random reads, 30% random writes, 2 jobs, 16 iodepth) on the attached PVC as and when the pod is started. Total 15 PVCs will be created in this case, and one PVC will get attached to one FIO pod.
Note: If you get an error "forbidden: unable to validate against any pod security policy" after applying the above statefulset, then the pods will not get created. You will need to first create and apply Pod Security Policy (PSP) to the Tanzu Kubernetes Cluster.
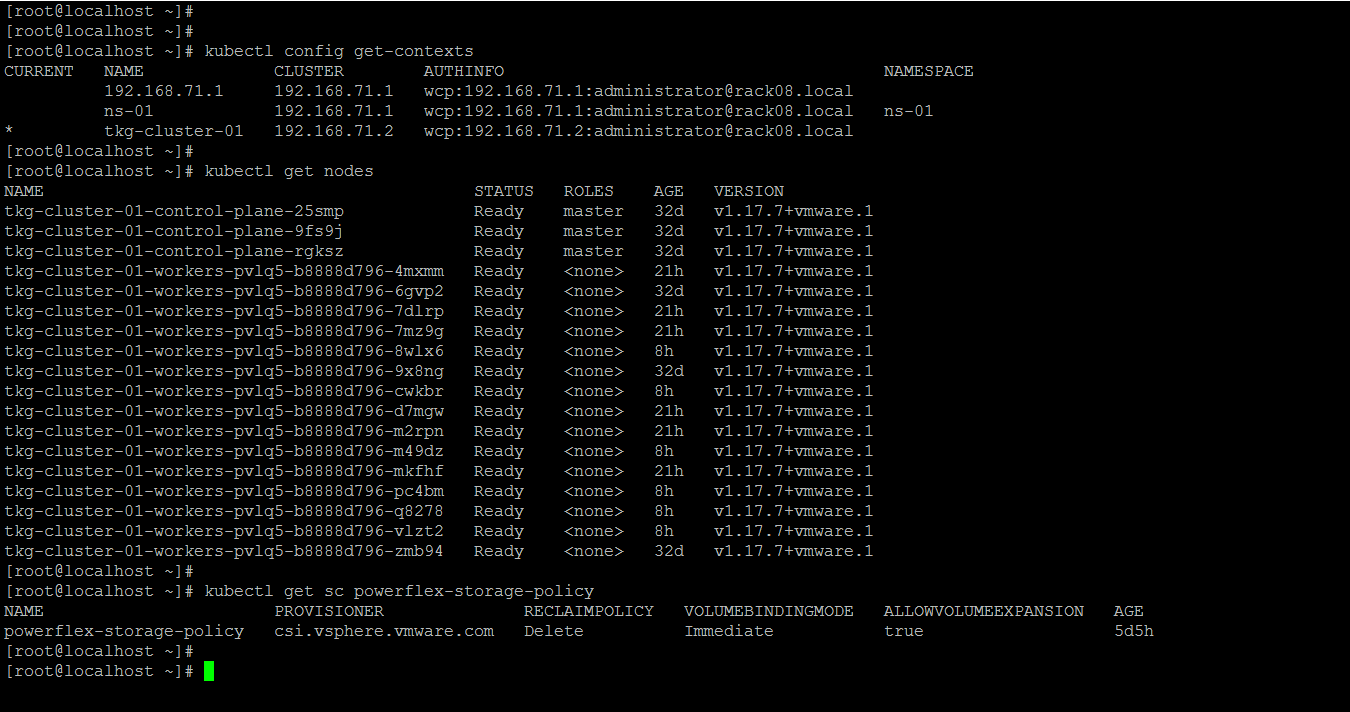
Following is an overview of my vSphere with Tanzu setup:
Tanzu K8s control plane nodes/ master VMs: 3
Tanzu K8s worker nodes/ VMs: 15
Contexts, Tanzu K8s cluster nodes, and storage class.
kubectl apply -f https://gist.githubusercontent.com/vineethac/7c9f6ce2b72868b8832a4404b79ebba2/raw/980f9d6c24c10b1b7b39b20d80c15a9f2ee6c4f1/fio_ss.yaml -n <namespace name>
You can see that it took roughly 6 minutes to deploy 15 FIO pods and corresponding PVCs. The time may vary depending on whether the FIO image is locally available on the nodes, available resources on the nodes, etc.
As and when each pod is created, FIO will automatically start IO stress on it. IOs will be read/ written into the attached PVCs. As I mentioned earlier, I am using a storage class "powerflex-storage-policy" and this is associated with a VVOL datastore backed by a PowerFlex storage pool. In this case, all the PVCs are created in a PowerFlex VVOL datastore.
You can also see multiple volumes in the PowerFlex UI and all those volume names starting with "vasa" are externally managed by the PowerFlex VASA provider. The performance of each volume can be also be monitored using the PowerFlex UI.

Note: When the duration mentioned in the FIO test is over, the pods will get restarted and the IO stress will also start. To modify the FIO parameters you can use kubectl edit statefulset fiopod-statefulset-multipod -n fiogit modify required parameters and save it. After saving it the new changes will get applied automatically. Once you are done with the testing, you can delete the statefulset and the corresponding PVCs using kubectl delete command. This method is useful when you want to test something quickly or if you have only less test profiles. If you have many test profiles with varying block sizes, iodepth, etc, then you will need to build a small script or something to automate the process.
Hope it was useful. Cheers!
Related articles
References